FPGA SoCを用いて CNNの演算を効率化する方法について
はじめに FPGAでの効果的な実装¶
FPGAを用いてdeep learningの識別処理を行うことによる優位性として
- 回路規模
- 消費電力
が挙げられる。 ネットワーク構成があらかじめ指定されている場合にはメモリ管理ユニットやDMAの動作が不要になり回路規模、消費電力がその分削減されること、 動作も予測可能なことから待機時間を削減できクロックあたりの計算処理量を増大できることなどに起因する。特に畳み込みニューラルネット(CNN)では各層の要素変数を計算するのに使われる前の層の要素が空間的に局在し共有されることが多いので効率化が行いやすい。
また設計、使用する際に注意すべき点として
- 動作周波数
- 可塑性、拡張性
- 実装難易度、正確さ
が挙げられる。効率的に動作が可能なネットワーク構成は制限される上、その組み合わせ内で期待通り動作しているかを確認するためにシミュレーションやオンチップデバッガ(signaltap, chipscopeなど)での検証を行うことが望ましい。 一般にFPGAの動作周波数はデスクトップ、サーバー向けCPU, GPUより数倍から10倍程度低い。識別のスループットの高さよりも電力効率の高さを訴求点とするのが現実的である。
また多層のCNNではパラメータのサイズが大きくなる(AlexNetで238MB, VGG-16で528MB)。組み込み系では畳み込み係数、バイアス係数(パラメータ)を保存することが困難な為量子化、圧縮することが必須となる。圧縮したパラメータを伸張する際にどのようなアルゴリズムを使用するのが効率的になるのかはネットワーク構成や学習で得られたパラメータの値に依存するため変更が容易なソフトウェアで行う事が望ましい。
画像入力、物体識別の結果や位置、あるいは処理された画像を出力とする場合が想定されるがマルチスペクトル画像や音声情報をフーリエ変換したデータなども取り扱うことができる。
以下ではXilinx社のSoC ZYNQを用いたCPU, FPGAを連携させたCNN識別動作の実装について説明する。
アーキテクチャの例¶
全体¶
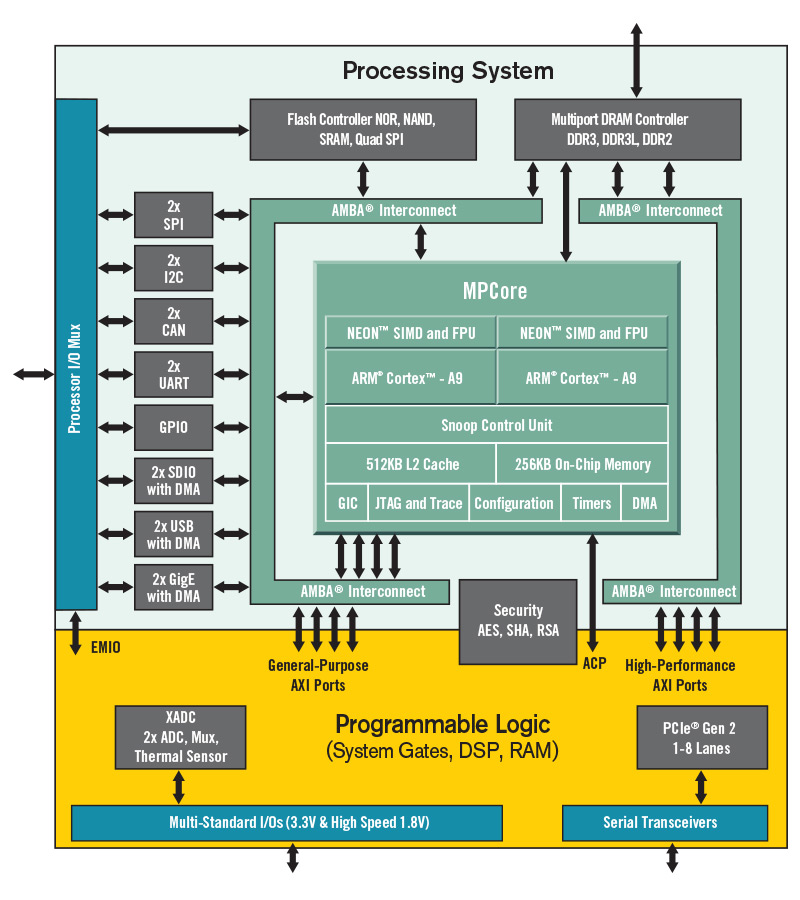
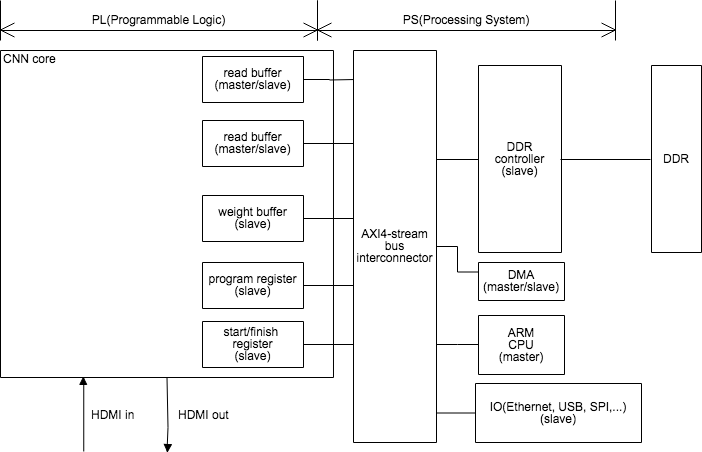
ZYNQはARM CPUと周辺回路からなるPS(processing system)と、FPGA部分のPL(programmable logic)から構成される(参考)。 PL部分は畳み込み演算専用回路(以後CNN coreと呼ぶ)として使われ、AXI4-stream busでARM CPU, DDRコントローラーと接続される。その他のIOはHDMIなどの画像入出力はCNN coreと直結あるいはAXI4-streamを介したDDR DRAM経由、USB, EthernetはCPUとAXI DMAを介してDDR DRAMと間接的に接続されている。
{kind=link}
CNN core¶
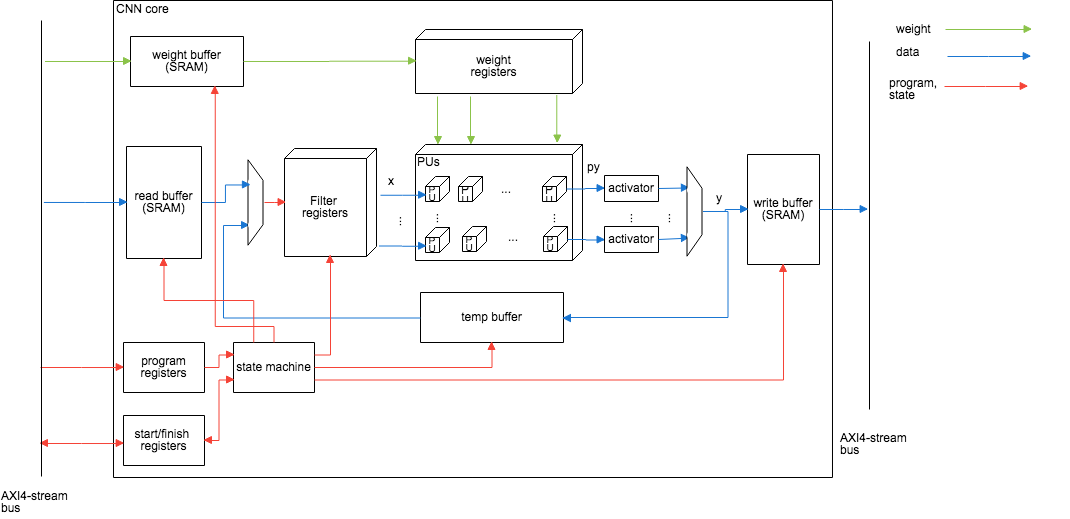
CNN coreは様々な組み合わせの畳み込み演算を行うための専用回路である。 積和演算回路の集合体(PUs)とそこに計算対象のデータを供給するレジスタ(Filter registers, weight registers), さらにそこに値を供給し、DRAMからの読み書きデータを一時的に保持するSRAMで構成されたバッファ(read buffer,write buffer,weight buffer, temp buffer) とそれらを制御するステートマシンから構成されている。
層の形状は基本的には3次元テンソル(幅、高さ、チャネル数)=(w,h,ch)で表される。ある層の値xと畳み込みパラメータweightを掛け合わせて出力yを計算する処理$$y_{l,j,ii,jj}=Activate(\sum_{n,m \in kernel} {\bf w}_{l,j,i,m,n}{\bf x}_{i,jj+m,ii+n}+bias_{l,j})$$をコードで書くと
for l in range(layer_num):
for jj in range(row_num[l]):
for ii in range(colmn_num[l]):
for j in range(outchannel_num[l]):
py=bias[l][j]
for m in range(kernelsize_y[l]):
for n in range(kernelsize_x[l]):
i in range(inchannel_num[l]):
py=py+weight[l][j][i][m][n]*x[i][jj+m][ii+n]
y[l][j][ii][jj]=Activat(py)
のような多重のループで構成される(ActivateはReluなどの活性化関数)。 CNN coreはこのうちのiiのループをパイプライン化しi,j,m,nに当たるループを可能な限り並列化することを意図した回路構成になっている。
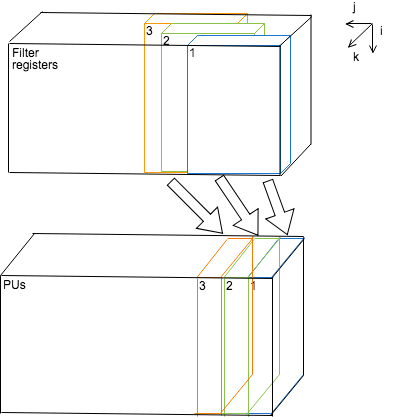
PUs, weight registers, filter registers, activator¶
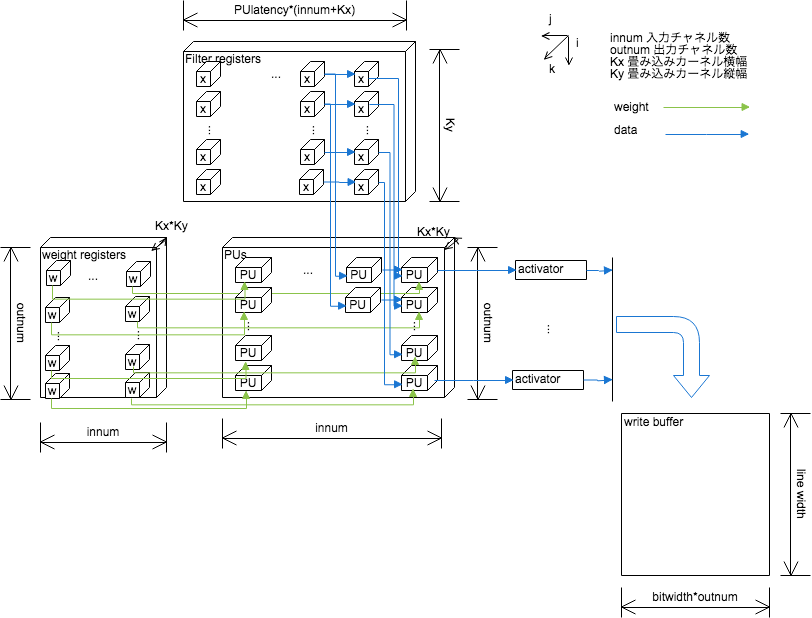
パイプラインと並列化の恩恵を可能な限り多くのネットワーク構成に対応するために積和演算を行うProcessing Unitを前後に連結したものが縦横に並列した直方体で図示できるような3次元的な構造をとるようにする。これをProcessing Units(PUs)と呼ぶ。 PUsに入力値、畳み込み係数を提供する部分はレジスタで実装し、同時に複数のPUに同じ値を提供できるようにする。各PUの入力は重み行列の要素と前の層の中間出力値、および図の左側にあるPUの出力である。重み行列の要素と中間出力値の積に左側にあるPUの出力をたし合わせ右側のPUに出力する。
図の最も左にあるPUの入力はバイアス値(bias)であり、図の最も右にあるPUは畳み込み範囲ごとに並列に計算された値をたし合わせてその結果はwrite buffer(またはtemp buffer)に送られる。
畳み込み係数、バイアス係数は固定小数点精度を想定している。また入力データのbit精度と畳み込み係数のbit精度を異なるものとすることもでき、CPU,GPUなどの汎用性の高いプロセッサに比べ回路規模、消費電力の点で優位になる。
filter registersは中間層の結果(上のコードのx)を保持する部分で畳み込み計算で使い回すために2次元的な構成を取れるようになっている。層内の計算が横方向に進むのに応じてPUのレーテンシー分のクロックサイクルのうちに1回だけ図の右方向に格納した値をシフトさせていく。図示したようにfilter regsは
(PUのレーテンシー*(入力channel数+畳み込みフィルタ横サイズ)
の数だけ入力値のbit幅分のレジスタが前後方向に用意され、それが入力channel数*畳み込みフィルタ縦サイズだけ並列している。層の端での折り返しなどやpaddingの処理はライン初めのレジスタ初期化で同じ値を用いるなどの方法で行う。
filter registers, PUs間では入力値の転置に相当する処理をしている形になる(下図)。
入力channel数, 出力channel数が小さい場合にはweight registersには一つの層で用いる全ての畳み込みパラメータの要素が用意されている。この場合1層の計算処理中にweight bufferから書き込みが行われる事はないので後述するCPUによる畳み込みパラメータの伸長処理の結果をweight bufferに書き込み次の層の計算処理の準備をする事ができる。 出力channel数が大きい場合には一部のみがweight bufferから順次ロードされる。
全ての入出力channel数、畳み込みkernelサイズに対応することは回路の組み合わせの点から困難で動作速度的に不利になる場合が予想され、偶数のみ、一定値以下のkernelサイズなど組み合わせを制限する方法も考えられる。近年では畳み込みフィルタサイズを小さくし層の数を増やすネットワークが比較的高い性能をあげている事が報告されていることからそのようなネットワークに特化する方向も考えられる。
畳み込みの計算では各層内の位置的に隣接する値のみを入力として用いる。DRAMに中間層単位の計算結果、SRAMに層の横数ライン単位の計算結果、レジスタには数ライン、チャネルのさらに一部分の計算結果を保持するようになっておりこれはCPUで計算するアーキテクチャにおける記憶階層に相当する。
Relu, sigmoidなどの活性化関数と必要に応じてmax pooling関数をモジュールとしてPUsの出力とwrite bufferの間に複数用意し計算に用いる。
read buffer¶
DRAMから処理対象の畳み込みカーネルの縦幅の数だけのラインの中間層の値を読み出し保持し、filter registerへと出力する。 bit幅の変換、クロックの載せ替えも主要な機能となる。同時に処理可能な入力チャネルの数が少ない場合は並列に出力し、 CNN coreの限界を超える場合は分割して一部ずつfilter registerへと出力する。
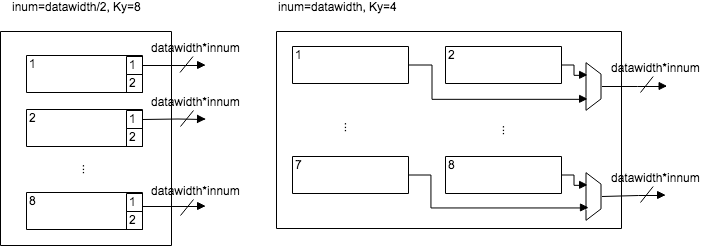
read buffer内部はサイズの同じ複数の小さなSRAMで構成されている。例として8個のSRAMで構成される例を以下に示す。
畳み込みフィルタサイズ(Ky)が大きい場合には小さなSRAM一つ一つが1ライン分のデータを並列に出力する (図の左側)。 図の左側ではさらに入力チャネル数(innum)が小さい場合もかねて図示しており小さなSRAMのbit幅のうちの一部のみが交互に出力される。
畳み込みフィルタサイズ(Ky)が小さい場合には小さなSRAMを連結して1ライン分のバッファとし、ライン途中で出力を切り替えする(右側)。
write buffer¶
PUsで計算され活性化関数(activator)を適用された値を保持し、DRAMへ書き込むためのSRAMバッファである。bit幅の変換、クロックの載せ替えも主要な機能となる。 AXI4 streamまたはDDRコントローラーのバス幅と同じだけの幅をもち、出力チャネル数データのビット長がバス幅よりも小さい場合はアドレスの小さいところから順番に書き込み(図の左)、出力チャネル数データのビット長がバス幅よりも大きい場合はアドレスを飛ばしながら書き込んで最終的に層内の同じ座標のデータが隣接するようにする(図の右)。
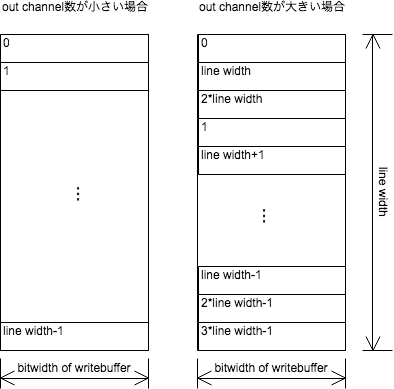 四角内の数字、変数は書き込む順番
四角内の数字、変数は書き込む順番
temp buffer¶
計算結果の層のサイズが小さい場合に次の層の計算のための値を保持してDRAMアクセスのための時間と電力を節約するためのSRAMである。
またLeNetなど物体識別で用いられるは最終段に畳み込みでない層(fully connected layer)が存在する。これを計算する場合にはfilter regに保持した値を固定した状態で積和計算を行いtemp bufferに書き込んだ値を再びを読み出して計算するという処理を逐次的に行う必要がある。
論理合成時にtemp buffer, read buffer, write bufferの各SRAMにどの程度の容量を割り振ると効率的になるかはネットワークの形状に大きく依存する。 read buffer, write bufferは同程度のサイズだがtemp bufferに割り振る割合を大きくして特定のネットワークの場合にDRAMアクセスを少なくし消費電力削減を図る方法が考えられる。
ステートマシンとプログラム¶
ステートマシンでどの層のどのチャネル、2次元座標内のどの位置に関する計算を行なっているかを保持し、そこから各bufferへの読み書きの指示とどこを読み書きすべきかのアドレスの出力を行う。
bufferの制御は基本的にはライン(層の横幅)単位で行われる。処理対象のラインの演算開始前にDRAMからread bufferに 演算終了後に計算結果がwrite bufferからDRAMへと書き込まれる。read buffer, write bufferをダブルバッファ化することで演算とDRAMへの読み書きは同時に行う事ができる。
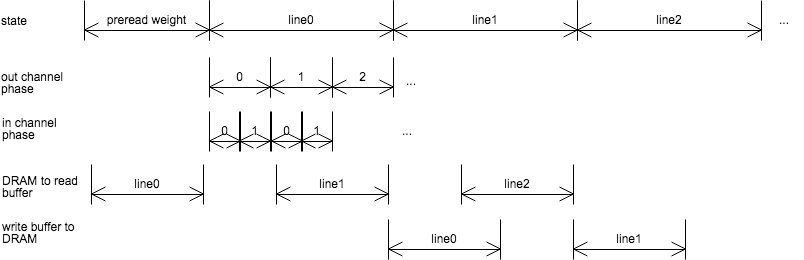
学習に用いたネットワークの情報から層の数、各層の幅、高さ、チャネル数、計算結果をtemp bufferに格納するか否かなどの情報を取り出しステートマシンで使用する。この情報をプログラムと呼ぶ。 各層のin,outのチャネル数からどれだけのチャネル分の畳み込みを並列に処理するかが決定され、プログラムに記載される。 ラインの長さに応じて処理の分割、統合を行うことも考えられるがその有無もプログラムに書かれることになる。
パラメータの圧縮¶
ニューラルネットの畳み込み係数(パラメーター)の圧縮方法として
- 量子化(浮動小数点数精度から固定小数点制度への変換を含む)
- 隣接差分値の保存
- 疎行列フォーマットの利用 (Zero Run Lengthと等価)
- エントロピー符号化(ハフマン符号化、rangecoderなど)
- 行列分解、テンソル分解
などが考えられる。 このうち量子化は非可逆圧縮でありFPGAでは2値化、3値化が効率的な方法として注目されている。 ほとんど識別精度を落とさずに2値化、3値化を行う方法も知られているが、既存の学習結果の活用を想定すると8bit~16bit程度の固定小数点精度での計算が望ましい。畳み込み係数のbit幅が固定している場合にはそのサイズをparameterとしてCNN coreに渡して合成することで回路規模や速度を効率化する事ができる。 例としてtensorflowでの学習済みパラメーターの量子化は https://www.tensorflow.org/lite/performance/post_training_quantization で行うことができる。
CNNの畳み込み係数はフィルターとしての性質を持ち1つのチャネル内の値は滑らかに変動する性質を持っているため差分値にZero Run Length符号化、ハフマン符号化などを施す方法が有効である。一方で量子化の極端な形であるpruning(枝刈り)を適用すると値が0となるパラメーター成分が多くなるのでZero Run Length符号化が有効となりやすい。
また畳み込み係数行列のもつ対称性から(近似)行列分解、テンソル分解も有効である(https://arxiv.org/abs/1711.10781 )。
例としてある層に対応する$w_{i,j,n,m}$を要素としてもつ4次元の畳み込み係数をCP分解という方法で分解すると
$$w_{i,j,n,m} = \sum_{r=1}^R \lambda_r a_{r,i} b_{r,j} c_{r,n} d_{r,m} +\epsilon_{i,j,l,m} \simeq \sum_{r=1}^R \lambda_r a_{r,i} b_{r,j} c_{r,n} d_{r,m}$$
という形に書ける事が期待される。元々のwのサイズが$I \times J \times N \times M$であったとすると近似後のa,b,c,dの合計サイズはR*(I+J+N+M)程度となる。 近似を行わない場合でも残差$\epsilon_{i,j,l,m}$の要素が小さな値であればその分必要となる記憶容量は少なくなる。 右辺の形から左辺の形に戻す処理が必要になるが後述するようにCPUにその計算を行わせる事ができる。
行列分解と2値化を同時に行う方法も知られている。
ARM CPUの利用¶
ZYNQにはARM CPUがハードコアとして実装されているのが大きな特徴となっている。これはP これを有効に利用したいが畳み込み演算はPLの専用回路CNN coreで行い、そのステートマシンや計算途中のデータの転送も比較的単純で予測可能なため 可能な限り遅延を少なくしPLで行うのが望ましい。 CPUを用いたDMAを用いるよりは そこで残された処理として圧縮された畳み込みパラメータを伸長する処理をARM CPUで行うこととする。層の形状や実際のパラメータの分布によって圧縮の必要性の有無や適切なアルゴリズムが変わりうるのでこれをソフトウェアで行うのは可塑性を高める点で利点がある。
またEthernet, USBなどを使って画像や計算結果の入出力をおこなう際にはlinux上のプロトコルスタックを使用すべきである。そのためlinux上で動くプロセスとしてパラメータの伸長処理をソフトウェア実装すべきである。
画像や計算結果の入出力はCNNの識別処理の前後、層別のパラメータの伸長処理はCNNの処理中に行われるので同時に実行されることはなく1つのCPUで ARM上のlinuxでパラメータの伸長処理、CNN coreへの書き込みを行う時にはCNN coreでの前の層の計算完了を割り込み信号(参考)として計算を開始し、1層分のパラメータに関する処理が完了した際にはCNN core内のレジスタに完了フラグを書き込みそれを伝えるものとする。
この動作では伸張処理と畳み込み演算が同時には行われず識別に時間がかかってしまう。weight bufferをダブルバッファ化し、当該層の計算が始まる前にあらかじめパラメータを伸張し、あとでフロント、バックバッファを切り替える方法が考えられる。
AXI4-stream busによるDRAMコントローラーとの接続¶
圧縮された状態のパラメータと各層の中間計算結果は容量が比較的大きい為を格納するのにはDRAMを用いる。 ZYNQではDDRコントローラーはPS領域でのみ使用できるがAXI4-stream busを用いればPLにあるCNN coreからアクセスすることが可能である。
1つのバスにARM CPU, CNN core、DDRコントローラーを繋げることになる。 CNN coreのread buffer,writebufferとCPUをマスター, DDRコントローラーとweight bufferをスレーブとした構成になり、AXIマスターとしての優先度はCNN coreが高くARM CPUが低い形になる。
PL内の1つのモジュールに複数のAXIインターフェースを持たせることはできない(参考) が、あらかじめCNN coreを構成するwrite buffer, read buffer, weight buffer, 結果、状態保持用レジスタファイルとその他の部分を別々のIPとしてSystem Verilogで記述、作成し接続するという方法が望ましい。 またwrite buffer, read bufferは直接AXIに接続するのではなくマスター、スレーブのインターフェースモジュールを作成した上で通常のSRAM風インターフェースとの 接続を行う形が良い。
CNN core内部では幅広く並列性をとることができるのでデータ転送はCNN core-DDRコントローラー間で律速となる。 データ処理速度をバランスさせ、消費電力を最適化するためにCNN coreの動作周波数を落としread buffer,write bufferでクロックの載せ替えを行う構成も考えられる。
IOとの接続¶
PYNQボードのようなHDMIインターフェースをもつボードの場合は入出力それぞれのRGB信号を直接CNN coreへ接続することで構成を単純化させることができる。

HDMI入力からクロックが供給されるのでそれに同期してPUsも動作させることが可能である。その場合識別処理のフレームレートは入力画像のフレームレートに比べ層の数に応じて小さくなってしまう。DDR,CPUのクロックとの載せ替えはwrite buffer, read bufferで行われる。
USB,Ethernetからの画像入出力、識別結果、画像内位置情報の出力に関してはARM上のlinuxを介したDMA転送を行うのが良い。 そのためCNN coreが入出力画像を直接IOから受け取るのではなく、DMA経由でDRAMに読み書きされたものを使用する形になる。
発展的内容¶
より複雑なネットワークの実装¶
上記の構成例はAlexnet, Lenetなどの出力が画像に写っている物体の種類などのカテゴリカルな量である場合を想定している。 超解像、自動彩色 画風転移などの出力が入力と同程度のサイズ、チャネル数の画像である場合にも用いることが可能である。
ResNet, U-Netのような並列に計算した層の出力を途中でmerge(kerasでいうconcatenate)するような回路構成の場合複数の層を同一のものとして並列に計算するか、あるいは途中まで計算した層の結果を一時的に保管しておく必要がある。 DRAM,SRAM内のどこに一時的に保持するか(先頭アドレス)、保持した値をどの層で読みだし、read bufferに格納することでmergeして用いるかを指定できるようにプログラムを拡張する必要がある。
学習プロセス¶
固定された回路でパイプライン、並列化された計算が得意であるというFPGAの特質を考えると 訓練画像、データの読込シーケンスが複雑になること、 浮動小数点精度で学習することが望ましいこと、さらに下記のような複雑な計算を行わなければいけないことから学習プロセスはGPU, CPUなどFPGA外部のデバイスで行うことが望ましい。
batchごとに累積された誤差、例として平均2乗誤差 $$loss=\sum_{(x,y,c) \in pixels}{| y_{train} - y_{output}|^2}$$ に対して重みパラメータ$w_{lijnm}$の推定に最も単純な確率的勾配効果法(SGD)を使った場合は更新式は $$w_{lijnm}=w_{lijnm} - \epsilon \frac{\partial loss(w_{lijnm})}{\partial w} $$ となる。添字lijnmに対してlossの微分を計算しなくてはならない。lossの式を構成する$y_{output}$は $$y_{output}=f_l(f_{l-1}(f_{l-2}(...),w_{l-1..}),w_{l}) $$ と各層lの活性化関数$f_l$を順次適応して行ったものの微分であるためその導関数$\frac{\partial f_l}{\partial w}$の掛け合わせで表現される。 個々の導関数の式の形を求めるのは難しいことではないが、層の数とネットワーク全体の中での位置(添字l)、結合の仕方に応じた導関数の計算をCNN coreのような専用回路で行うことは難しく、GPUなどの汎用性が高いプロセッサで行うほうが効率的である。
その他利用できそうな機能¶
ハイエンド製品Zynq UltraScaleなどではデュアルコア、ARMのGPU Maliが搭載されている。これを活用する方法は上記の構成では見出せない。動画デコード、エンコードや独立した画像処理機能、あるいはMaliを用いたfine tuning、テンソル分解した畳み込みパラメーター行列の復元などが考えられる。
DPS最適化¶
積和演算は論理合成時にFPGAに搭載されたDSPに割り当てられる場合が多い。特にXilinx社の製品はAltera社に比べ数が多い傾向にある。 一般的な積和演算に比べdeep learningの識別処理では少ないビット幅での演算が盛んに研究されているが、かえってDSPの使用効率が悪化する可能性もある。 逆に2値化、3値化されたパラメータの演算をLUTのみで実装する方法も考えられる。 判別精度はシミュレーションによって計測すべきだが回路規模、消費電力は論理合成、演算実行によって実測するのが望ましい。
参考¶
Xilinx公式ドキュメントは除く
- CNNの基礎と研究の進展について http://cs231n.github.io/convolutional-networks/
- AXI4-stream busについて http://www.tokudenkairo.co.jp/blogtemp/seccamp17_slide2.pdf
- ネットワーク量子化について https://developer.smartnews.com/blog/2017/03/neural-network-quantization/
- テンソル分解の利用について https://medium.com/@nwerneck/tensor-decompositions-the-special-sauce-of-deep-learning-633b2ee37972
- 「A Survey of FPGA Based Neural Network Accelerator」の日本語訳 http://cparch-mclearn.blogspot.com/2018/02/a-survey-of-fpga-based-neural-network.html